零基础入门 Stable Diffusion - 无需显卡把 AI 绘画引擎搬进家用电脑
我从小特别羡慕会画画的伙伴,他们能绘出心中所想,而本人水平最高的肖像画是丁老头。接触 Stable Diffusion 后,我脱胎换骨,给自己贴上了「会画画」的新标签。
Stable Diffusion 是一个「文本到图像」的人工智能模型,也是唯一一款开源且能部署在家用电脑(对硬件要求不高)上的 AI 绘图工具,可以在 6GB 显存显卡或无显卡(只依赖 CPU)下运行,并在几秒内生成图像,无需预处理和后处理。
体验 AI 绘图可借助在线工具 Hugging Face、DreamStudio 或 百度文心。与本地部署相比,Hugging Face 需排队,生成一张图约 5 分钟;DreamStudio 可免费生成 200 张图片,之后需要缴费;百度文心能用中文生成图片,但仍处于 beta 阶段,未正式商用。更重要的是,这类在线工具对图片的调教功能偏弱,无法批量生成图片,只能测试体验。
如果想生成大量 AI 图片,可以通过 Docker Desktop 将 Stable Diffusion WebUI Docker 部署到家用电脑,从而免费实现 AI 文字绘画,不再被在线工具所限制。Mac 用户建议选择 Stable Diffusion 的 invoke 分支,部署报错参考 InvokeAI 文档,M1/M2 Mac 推荐使用更简便的 CHARL-E 或 DiffusionBee。
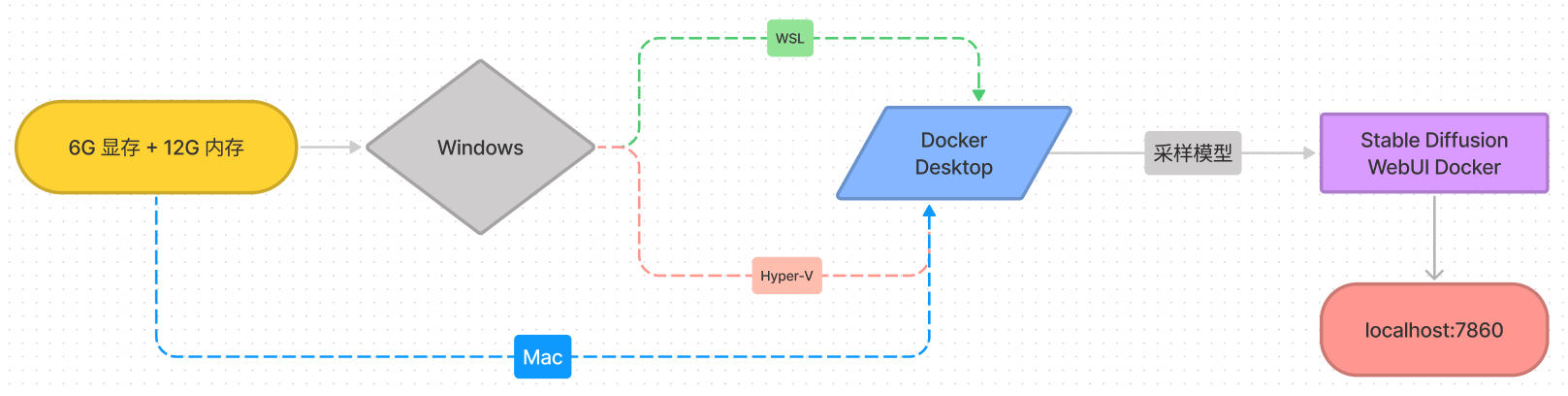
本文以 Windows 平台为例,下面会依次介绍环境配置,Stable Diffusion 安装和基本使用方法。
Docker 环境配置
本方案基于 Docker 配置,而 Docker 实质上是在已经运行的 Linux 下制造了一个隔离的文件环境,它必须部署在 Linux 内核的系统上。[1] 因此,Mac 不用特别配置,而 Windows 系统想部署 Docker 就必须需要安装一个虚拟 Linux 环境,配置 WSL 或是启用 Hyper-V,二选一即可,推荐使用子系统 WSL(占用系统盘 30G 的空间)。
安装 WSL
在管理员 PowerShell 输入命令 wsl --install,之后终端会默认安装 Ubuntu。系统下载时间较长,注意别关机。[2] 安装 Ubuntu 完成后,按提示设置 Ubuntu 账户和密码。
启用 Hyper-V
以管理员身份打开 PowerShell 控制台,输入命令 Enable-WindowsOptionalFeature -Online -FeatureName Microsoft-Hyper-V -All。[3] 重启电脑后,将开启 Hyper-V。
Linux 路径(Windows)
配置 WebUI Docker 要进入 Linux 环境,因此 Windows 用户需将其路径转换为 Linux 路径,Mac/Linux 用户可忽略本步。
假设容器位于 D:\Desktop\stable-diffusion-webui-docker:
- 把磁盘符号改为小写,转换为
d:\Desktop\stable-diffusion-webui-docker - 添加
/mnt/前缀,转换为/mnt/d:\Desktop\stable-diffusion-webui-docker。因为 Windows 本地磁盘是挂载在 Linux 的 mnt 目录下的。 - 将反斜扛
\替换为/。最终得到 Linux 路径/mnt/d:/Desktop/stable-diffusion-webui-docker。
配置 Stable Diffusion
安装 Docker Desktop
按平台选 Docker Desktop 版本,安装后点击左侧的 Add Extensions,推荐 Disk usage 扩展,便于管理 Docker 存储空间。
下载 WebUI Docker
然后,下载 Stable Diffusion WebUI Docker 配置包 或 阿里云盘聚合版,将其解压到指定路径。聚合版包括相关依赖,因此文件较大。之后更新 WebUI Docker,也是按上方步骤重新构建容器即可更新 Stable Diffusion。
分支介绍
目前 Stable Diffusion 有 sygil、auto、auto-cpu 和 invoke 四个分支。如果要更换分支,则更改镜像构建命令 docker compose --profile [ui] up --build,将 [ui] 替换为所需的镜像名即可。原本的 hlkcy 分支更名为 sygil,原本的 lstein 分支更名为 invoke。
- sygil:界面直观,最高分辨率为 1024x1024,镜像构建命令为
docker compose --profile sygil up --build。 - auto(推荐):设置模块最丰富,显示绘画过程,支持随机插入艺术家、参数读取和否定描述,最高分辨率为 2048x2048(高分辨率对显存要求更高),镜像构建命令为
docker compose --profile auto up --build。默认使用 6GB 以上的显存,如果你的显卡内存较低,则将配置中的--medvram改为--lowvram。A 卡用户注意修改 显卡设置。 - auto-cpu:唯一不依赖显卡的分支。如果没有符合要求的显卡,可以使用 CPU 版本,稍后的镜像构建命令为
docker compose --profile auto-cpu up --build。 - invoke:cli 端非常成熟,WebUI 端参数较少,能自动读取图片记录,适合无进阶需求的新手和 Mac 用户使用,镜像构建命令为
docker compose --profile invoke up --build。
构建 Stable Diffusion
启动 Docker Desktop,打开 WSL(Ubuntu)或 Mac 终端输入路径切换命令 cd /mnt/d/Desktop/stable-diffusion-webui-docker,该路径为 Stable Diffusion WebUI Docker 解压文件目录。然后,输入下方的部署命令。
# 自动下载采样模型和依赖包
docker compose --profile download up --build
# 上方命令需要 20 分钟或更长,完成后执行镜像构建命令
docker compose --profile sygil up --build
# auto 是功能最多的分支,可以选择 auto | auto-cpu | invoke | sygil | sygil-sl
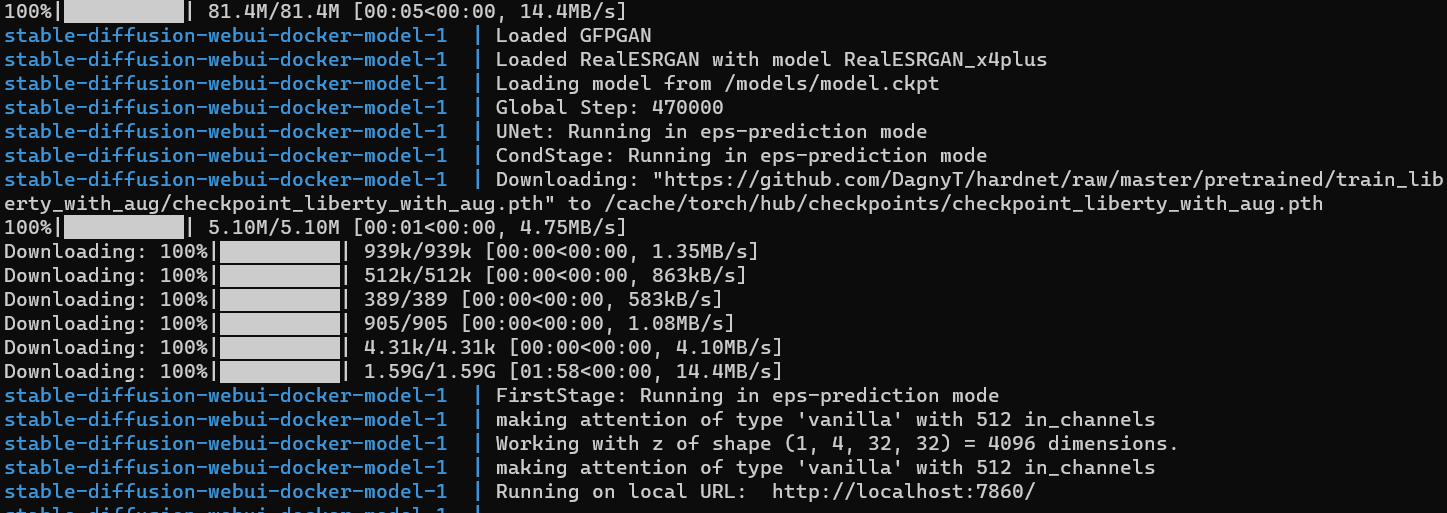
构建完成后,提示访问 http://localhost:7860/,你就可以在本地电脑上用 AI 生成图片了。[4]
使用说明
使用界面以 sygil 分支为例,其他分支的主题界面略有不同,但功能上并没有根本性差异。
启动 Stable Diffusion
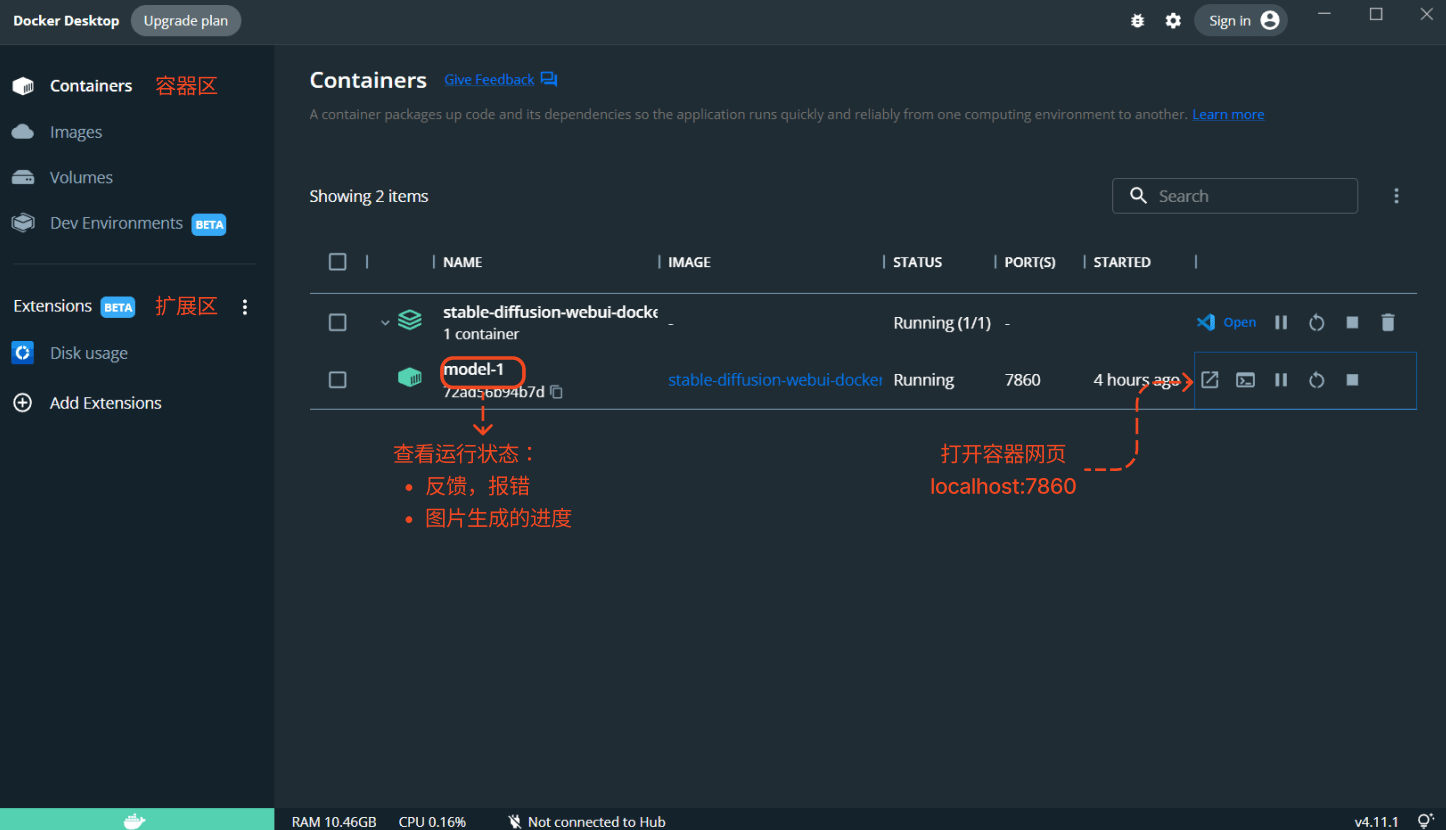
- 打开 Docker Desktop。
- 在 Containers 中选中分支容器,点击启动。
- 浏览器中访问
http://localhost:7860/。
Text-to-Image
Text-to-Image 是 Stable Diffusion 依据文字描述来生成图像。风景、创意画等崇尚空间结构的画作类型时,优先推荐竖图或者横图。人像类画作推荐 1:1 的方图,否则可能会出现两个或者多个人脸的叠加现象。生成图片的分辨率是有限制的,可以用 Upscale 放大结果图片。
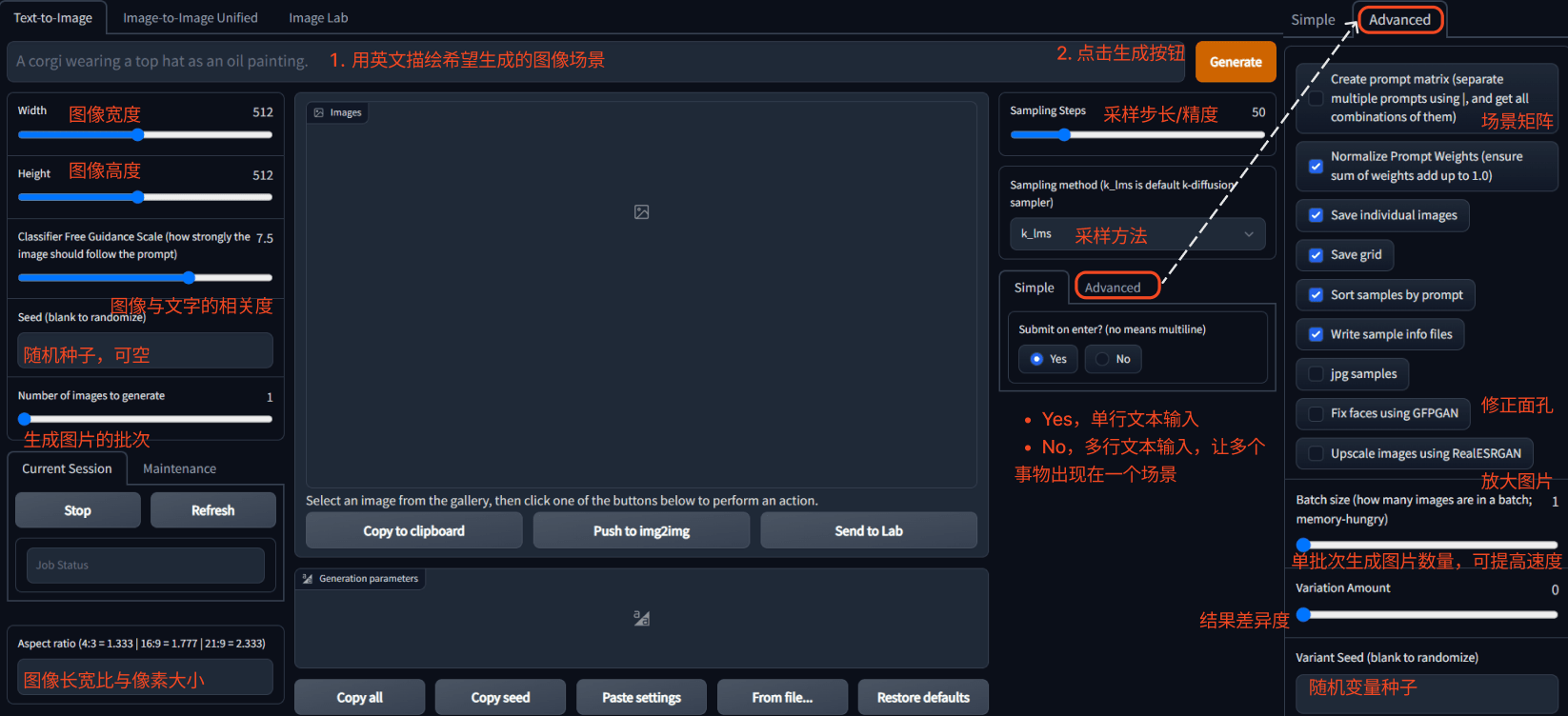
默认使用 Simple 简单模式,点击右侧按钮 Advanced,可查看进阶选项,使用进阶的场景矩阵、面孔修复和分辨率放大等多种功能。
Image-to-Image
Image-to-Image 依据文字描述和输入源图,生成相关的图像。该模式若以素描、结构画为来源图,可充分填充图像细节;若以细节充分的照片为来源图,则会输出差异较大的结果。更妙的是,你可以限定区域来生成图像,非常适合图像修改。
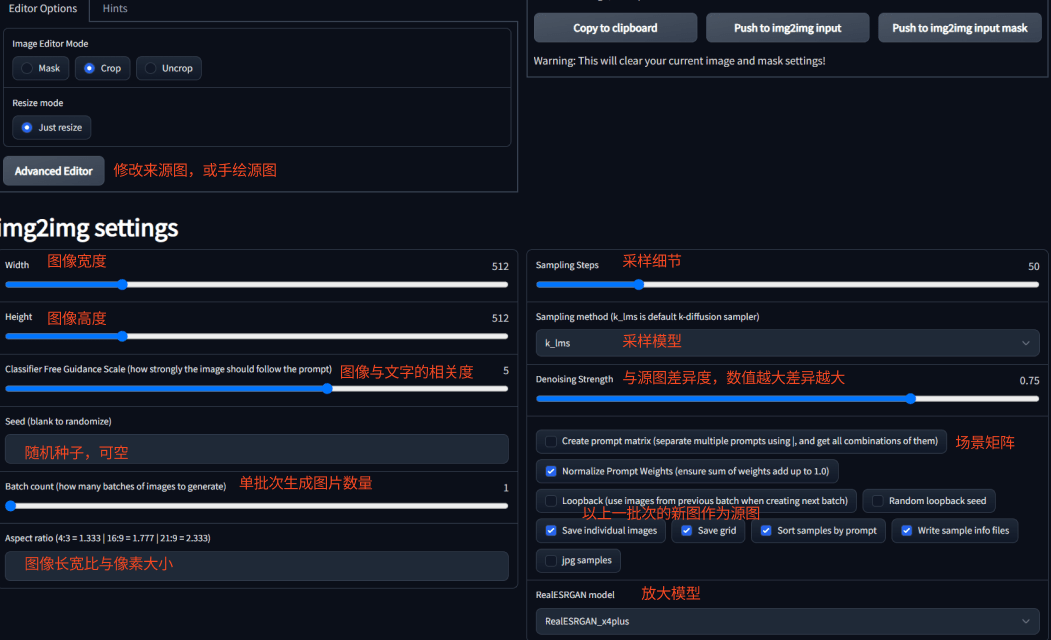
CLIP interrogator 会根据图像来生成文字描述。Denoising Strength 指与原图的差异度,建议在 0.75-0.9,魔改图片可以设为 0.5 以下。下图中的 Denoising Strength 只有 0.44,整体图片结构与要素没变,但结果如何你看到了。
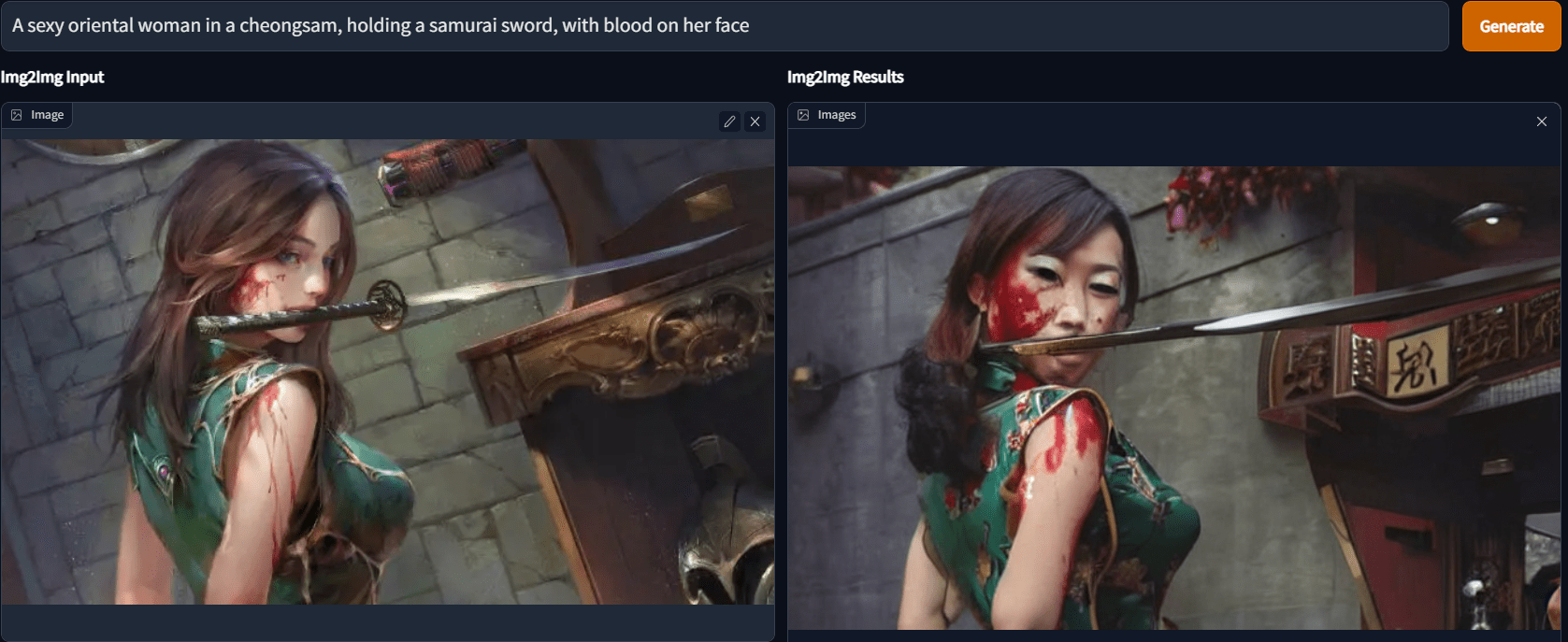
Image Lab
Image Lab 能批量修正面孔和放大图片分辨率。
Fix Faces 是通过 GFPGAN 模型来改善图片中的面孔,Effect strength 滑块可以控制效果的强度。但实际效果别报太高期许,下图右侧开启了 Fix Faces,只能说勉强有了五官。

Upscale 放大分辨率功能有 RealESRGAN,GoBIG,Latent Diffusion Super Resolution 和 GoLatent 四种模型,其中的 RealESRGAN 有普通与卡通两种模式,可按需选择。Upscale 图片主要消耗 CPU 与内存资源。
文字描述图像
Stable Diffusion 是以文字内容 (英文) 描绘一个场景或事物,从而决定你的画面中将出现什么。文字描绘是决定图像生成质量的关键因素。
样例:A beautiful painting {画作种类} of a singular lighthouse, shining its light across a tumultuous sea of blood {画面描述} by greg rutkowski and thomas kinkade {画家/画风}, Trending on artstation {参考平台}, yellow color scheme {配色}。[5]
常规描述
- 输入图像的对象、主体,比如一只熊猫、一个持剑的战士,不要描述动作、情绪和事件;[6]
- 画作种类:一幅画(a painting of + raw prompt)还是一张照片(a photograph of + raw prompt),或者 Watercolor(水彩)、Oil Paint(油画)、Comic(漫画)、Digital Art(数码艺术)、Illustration(插画)、realistic painting(写实画)、photorealistic(写实照片)、Portrait photogram(肖像照)、sculpture (雕塑) 等等,画作种类可以叠加。
- 画家/画风:建议混合多个画家的风格,比如
Studio Ghibli, Van Gogh, Monet,或描述风格种类,比如very coherent symmetrical artwork,将作品结构设为「连贯且对称」。 - 色调:yellow color scheme 指整个画面的主色调为黄色。
- 参考平台:Trending on ArtStation,也可以替换为「Facebook」「Pixiv」「Pixbay」等。

特征描述
除画面主体外,可以用其他具象物体和形容词来填充画面细节。描述词要具体,讲出你要的物体和它的特征。
- 次要元素:物体不要太多,两到三个就好。若要特别强调某个元素,可以加很多括号或者惊叹号,比如
beautiful forest background, desert!!, (((sunset)))中会优先体现「desert」和「sunset」元素。 - 人物特征:
detailed gorgeous face, delicate features, elegant, Googly Eyes, Bone, big tits, silver hair, olive skin, Mini smile; - 特定润色:
insanely detailed and intricate, gorgeous, surrealism, smooth, sharp focus, Painting, Digital Art, Concept Art, Illustration, Artstation, in a symbolic and meaningful style, 8K; - 光线描述:
Natural Lighting, Cinematic Lighting, Crepuscular Rays, X-Ray, Backlight,或逼真光照Unreal Engine; - 镜头视角:
Cinematic, Magazine, Golden Hour, F/22, Depth of Field, Side-View; - 画面质量:
award winning, breathtaking, groundbreaking, superb, outstanding; - 其他描述:细节和纹理、物体占据画面的大小、年代、渲染 / 建模工具等。
反向描述
negative prompt(反向描述)可以在 auto/auto-cpu 分支中设置,避免画面出现指定元素。
- 避免畸形:
ugly, blurry, out of frame, bad proportions, duplicate, deformed, mutation, morbid, mutilated, bad anatomy, disfigured, extra limbs, armless, legless, cloned face, extra heads, extra legs, extra arms, malformed limbs, amputee, poorly drawn face, poorly drawn hands, poorly drawn feet, fat, long neck, poo art, bad hands, bad art; - 避免裸体:
nudity, bare breasts。
prompt 参考
除画面主体描述外,其他要素并非必须。如果你只是简单尝试,输入主体「apples」即可。
如果你不知道生成什么图像,可以使用 promptoMANIA 、WEIRD WONDERFUL AI ART 按提示组合描述,或参考 AI 图库 PromptHero 和 OpenArt 上其他人分享的成品图和描述文案,比如
goddess close-up portrait skull with mohawk, ram skull, skeleton, thorax, x-ray, backbone, jellyfish phoenix head, nautilus, orchid, skull, betta fish, bioluminiscent creatures, intricate artwork by Tooth Wu and wlop and beeple, highly detailed, digital painting, Trending on artstation, very coherent symmetrical artwork, concept art, smooth, sharp focus, illustration, 8k
Prompt matrix
Prompt matrix 是 sygil 分支的功能,可以按不同条件组合生成多张相关但不同的画面,适合用于制作视频素材。[7] 此时,批次数量的设置会被忽略。
上方视频的调教词为 A mecha robot in World War II in realistic style|Shoot with another mecha robot|Bombed by planes|Missile drop|broken|Repaired|cinematic lighting。| 符号后的场景条件将进行排列组合,视频样例有 6 个场景条件生成 64 张图。
另外,我们可以指定场景条件位置,比如 @(moba|rpg|rts) character (2d|3d) model 表示 (moba|rpg|rts 三选一) character (2d|3d 二选一) model,也就是会生成 3*2 张图片。开头的 @ 是触发指定场景条件位置的符号,不能省略。
Textual Inversion
Textual Inversion(文本倒置)是 auto/auto-cpu 分支提供的功能,可以个人定制单词在模型中的含义。比如大众模型中医生多是白人男性,而我们可以输入 5 张亚洲女性照片并将其与 doctor 关联,经过 Textual Inversion 处理后的模型生成的医生形象将以亚洲女性为主。[8]
Textual Inversion 定制流程:
- Preprocess images:设置源图目录和输出目录。
- Create embedding(新建嵌入):建立模型属性。
- 待续。
常见问题
Docker Desktop failed
未正常安装/关闭 Docker 容器时,可能会报错 Docker Desktop failed to start/stop。
先删除 %AppData% 路径下的 Docker 文件夹,然后在 PowerShell 中输入下方命令,关闭 WSL 和 docker-desktop。最后,手动重启 Docker Desktop。
wsl --shutdown
wsl -l -v
wsl --unregister docker-desktop
wsl -l -v
Docker Desktop cannot start
Hardware assisted virtualization and data execution protection must be enabled in the BIOS 报错说明电脑没开启虚拟化。
在开机的时候多按几次 F2 或 DEL 进入 BIOS,然后设置中开启「Intel Virtual Technology」,AMD 则是将「SVM Support」设置为设置为「Enable」的状态;最后点击「F10」保存退出即可。
docker 命令失败
The command 'docker' could not be found 说明当前命令行确实 Docker 环境缺失,检查 Docker Desktop 是否启动。
端口访问被拒
Docker 容器原本运行正常,端口访问突然被拒绝了,显示 Error response from daemon: Ports are not available: exposing port TCP 0.0.0.0:7860 -> 0.0.0.0:0: listen tcp 0.0.0.0:7860: bind: An attempt was made to access a socket in a way forbidden by its access permissions。
在 Powershell 中输入 netsh int ipv4 show excludedportrange protocol=tcp 检查是否处于被排除端口范围,然后输入 reg add HKLM\SYSTEM\CurrentControlSet\Services\hns\State /v EnableExcludedPortRange /d 0 /f 开启端口。操作完成后,重启电脑即可解封端口。[9]
FileNotFoundError
再次架构容器时报错 FileNotFoundError: [Errno 2] No such file or directory: '/models/model.ckpt',这是架构位置错误导致的。此时,我们需要检查是否通过 WSL 输入的架构命令,并且 Stable Diffusion WebUI Docker 解压路径是否配置正确。
采样模型
采样模型是 AI 绘画的核心。2022.09.10 已支持自动下载采样模型,下方列表仅做参考。
- Stable Diffusion v1.4 (4GB), 将压缩包文件重命名为
model.ckpt。 - (可选) GFPGANv1.4.pth (340MB)。
- (可选) RealESRGAN_x4plus.pth (64MB) 和 RealESRGAN_x4plus_anime_6B.pth (18MB)。
- (可选) LDSR (2GB) 和 LDSR 配置,分别重命名为
LDSR.ckpt和LDSR.yaml。
最后
Stable Diffusion 还不能作为生产力工具,但它让设计变得简单,也让更多普通人打开了 AI 绘画的可能性。推荐大家实际部署玩下,让自己拥有更多的可能。
本文于「少数派首发」。




